Poprzednio ustaliliśmy gdzie mamy do czynienia z transakcjami elektronicznymi i jak one wyglądają. Obecnie jest miejsce na to aby przyjrzeć się im bliżej. Tak więc czas na zdefiniowanie podmiotu rozważań:
Transakcją elektroniczną nazywamy każdy rodzaj wymiany danych pomiędzy dwoma użytkownikami (żywymi, bądź automatami) sieci, który służy do ustalenia wzajemnego stanowiska 1(uzgodnienie protokołów, parametrów transmisji, autoryzacji lub uwierzytelnienia stron, ustalenia kosztów/ceny itp.) dla celu umożliwienia dalszej wymiany informacji, dóbr, dostępu etc.
Zrozumienie definicji umożliwia nam dokonanie klasyfikacji transakcji elektronicznych ze względu na ich charakter. Tak więc transakcje można podzielić na:
- automatyczne – gdzie transakcja jest wykonywana niejako automatycznie jako część większej całości i nie jest celem w samym sobie, a służy do przeprowadzenia kompleksowej operacji. Przykładem takiej transakcji jest próba pobrania poczty przez użytkownika, gdzie transakcją automatyczną jest procedura autoryzacji klienta poczty z serwerem pocztowym, ustalenie protokołów transmisyjnych, uwierzytelnienie użytkownika wykonywane automatycznie w procesie łączenia. W tym czasie użytkownik nie podejmuje żadnych decyzji co do rozwoju sytuacji – procedura wykonuje się niejako w tle całości (nie dotyczy wymogu podania hasła jeśli nie jest zapamiętane w profilu klienta poczty).
- inicjowane – gdzie transakcja jest inicjowana jako decyzja użytkownika. Przykładem takiej transakcji jest bankowa operacja zapłaty (przelew) wykonywana na życzenie użytkownika, poprzez wprowadzenie przez niego wymaganych danych (komu i ile).

Przy powyższym podziale nie sposób nie zauważyć braku „czystego” rodzaju podziału, bo przecież automatyczna procedura transakcyjna autoryzacji użytkownika dla pobrania poczty wykonywana jest zazwyczaj poprzez inicjację przez tego użytkownika w momencie, gdy zechce on pobrać pocztę elektroniczną. A w drugim przypadku zlecenie przelewu zainicjowane przez tegoż użytkownika wywołuje uruchomienia automatycznych transakcji umożliwiających bezpieczne przeprowadzenia tej operacji i samego zlecenia (autoryzacja logowania się do systemu transakcyjnego banku, autoryzacja sesji, autoryzacja protokołów szyfrujących itp.).
Inna klasyfikacja Transakcji Elektronicznych to podział ze względu na charakter ich zastosowania:
- Finansowe – gdzie podstawą i rolą transakcji elektronicznej jest doprowadzenie do finalizacji umowy finansowej pomiędzy dwoma użytkownikami. Taką transakcją jest np. nabycie dóbr poprzez e-sklep i zapłata za nie w konsekwencji tegoż nabycia.
- Protokolarne – podstawą i rolą transakcji jest uzgodnienie protokołów transmisyjnych pomiędzy dwoma użytkownikami sieci. Taką transakcją jest np. ustalenie rodzaju i parametrów protokołu niezbędnych do połączenia się np. klienta poczty elektronicznej do serwera tejże poczty.
- Autoryzacyjne – tutaj główną rolą takiej transakcji elektronicznej jest sprawdzenie czy wnioskujący o dostęp posiada niezbędną akredytację do tego aby taki dostęp otrzymać. W trakcie tego może następować uwierzytelnienie klienta. Przykładem takich transakcji jest np. zgoda na logowanie się do systemu chronionego hasłem.
- Sesyjne – jest to najbardziej powszechny rodzaj transakcji elektronicznych. Każda przeglądarka WWW 2WorldWideWeb wymienia informacje pomiędzy terminalem na którym została uruchomiona, a zasobem sieciowym z którym się łączy w celu zaoferowania użytkownikowi treści z tegoż serwera.
- Cookie – jest to i niezależna i powiązana z sesyjnością forma transakcji elektronicznych służąca realizacji połączenia pomiędzy dwoma użytkownikami sieci. Ma formę krótkiego kodu cyfrowego wygenerowanego poprzez serwer kontentu i przechowywanego w pamięci klienta (przeglądarki WWW).
Spis treści
Transakcje Finansowe
Tego typu transakcje można by nazwać metatransakcjami, albowiem w ich tle zachodzą wszystkie inne transakcje elektroniczne. Ten rodzaj transakcji będzie bliżej omówiony na późniejszych tematach zajęć.
Transakcje Protokolarne
Protokoły odpowiedzialne są za to, że klienty sieci nawzajem się „rozumieją”. Jest to część transmisyjna i jako taka będzie omówiona na następnych zajęciach.
Transakcje Autoryzacyjne
Transakcje Autoryzacyjne są absolutnie niezbędne by zapewnić bezpieczeństwo dla obu stron. Temat ten stanowi podstawę kilku następnych spotkań.

Transakcje Sesyjne
Z uwagi na podstawową i bezwzględnie najważniejszą część każdej operacji transakcyjnej w ramach WWW transakcje sesyjne zostaną omówione tutaj nieco bliżej, bez wdawania się w tematykę programistyczną.
WWW bazuje na protokole HTTP 3ang: HyperText Transfer Protocol lub HTTPS 4ang: HyperText Transfer Protocol Secure służącym do kodyfikacji zasobów w zrozumiały dla przeglądarki sposób. Zatem protokół HTTP to zasady wymiany informacji i współpracy programów. Programami są serwery i klienty5klienty, nie klienci – klient w rozumieniu bezosobowym jako maszyna (przy której oczywiście może siedzieć człowiek). Programy te wysyłają żądania (klienty) lub odpowiedzi (serwery). Przykładem klienta HTTP może być przeglądarka internetowa. Klienty mogą interpretować uzyskane odpowiedzi, na przykład przeglądarka internetowa potrafi wyświetlić stronę internetową, która została przesłana przez serwer.
Klienty wysyłają żądania. Każde żądanie powiązane jest z zasobem. Zasobem może być obrazek, strona HTML czy plik z kodem JavaScript. Sam protokół HTTP nie określa czym dokładnie jest zasób. Określa jedynie sposób w jaki można dostać się do zasobów. Każdy zasób ma swój unikalny identyfikator. Ten identyfikator to URI 6ang. Uniform Resource Identifier).
Protokół HTTP dokładnie określa format komunikacji pomiędzy klientami i serwerami. Komunikacja ta oparta jest na wspomnianych już żądaniach i odpowiedziach. Protokół HTTP określa format tych wiadomości.
Protokół HTTP jest bezstanowy. Oznacza to tyle, że każde zapytanie może być interpretowane w oderwaniu od pozostałych.
Podzbiorem URI są URL 7ang. Uniform Resource Locator. URI można traktować jako zbiór znaków który pozwala na unikalną identyfikację zasobu. URL natomiast poza tym unikalnym identyfikatorem zawiera informację dotyczącą “położenia” danego zasobu. Często określenia te stosowane są zamiennie.
Adres URL ma postać:
scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment]
Przykładowy adres URL może wyglądać następująco:
http://jarek:tajne@us.strzelaj.xyz:80/nie/ma/tej?strony=1#identyfikator
Zgodnie ze specyfikacją HTTP wielkość liter nie ma znaczenia w częściach scheme i host. Wielkość liter w pozostałych elementach ma znaczenie.
Poniżej opisane zostały poszczególne części adresu URL.
scheme
W praktyce ta część adresu używana jest do określenia protokołu, najczęściej widać tu http czy https. W uproszczeniu można powiedzieć, że HTTPS jest rozszerzeniem protokołu HTTP. To rozszerzenie pozwala na szyfrowanie połączenia pomiędzy klientem a serwerem.
user:password
user:password służą do uwierzytelniania. Uwierzytelnianie to proces, który polega na udowodnieniu, że klient wysyłający dane żądanie jest tym za kogo się podaje. Mechanizmu uwierzytelniania używany jest praktycznie w każdym serwisie gdzie są założone konta.
W tym przypadku nazwa użytkownika i hasło przesyłane są jako część URL. Nie jest to bezpieczne w przypadku używania protokołu HTTP. Nawet przy komunikacji protokołem HTTPS adres URL może być zapamiętany przez przeglądarkę. Daje to możliwość przechwycenia nazwy użytkownika i hasła. W związku z tym nie jest to bezpieczny sposób na przesyłanie hasła czy nazwy użytkownika i należy go unikać.
host
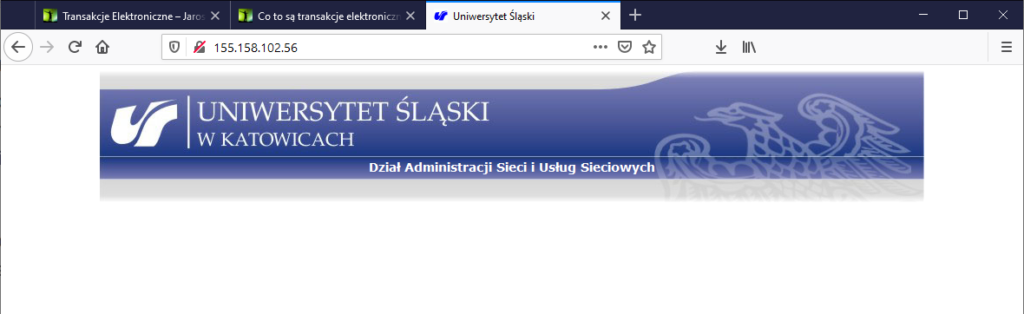
W przypadku protokołu HTTP sprowadza się to do nazwy domeny internetowej lub adresu IP. Przykładem domeny może być www.utracki.us.edu.pl. Odpowiadający mu adres IPv4 to 155.158.102.56.
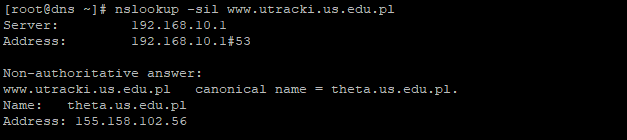
DNS 8ang. Domain Name System jest protokołem, który pozwala na tłumaczenie adresów IP na nazwy domen. Używanie samych adresów fizycznych nie jest często właściwe. I jak dla powyższego przykładu domena www.utracki.us.edu.pl ma adres IP: 155.158.102.56, tak należy pamiętać, że pod tym adresem może znajdować się wiele różnych adresów domenowych i wpisanie adresu IP w pole: adres przeglądarki może mieć nieoczekiwane działanie.
port
Port to numer. Numer ten jest wykorzystywany przez serwer. Serwer nasłuchuje ruch na danym porcie. Poprzez analogię można powiedzieć, że tak jak z numerem w bloku, domena to numer klatki, a port to numer mieszkania.
Protokoły mają swoje standardowe porty. Na przykład standardowym portem protokołu HTTP jest 80. Protokół HTTPS natomiast używa portu 443. W praktyce, ze względu na domyślne wartości, wskazanie numeru portu często się pomija, są one pobierane niejako automatycznie. Odpowiednia wartość pola scheme pozwala na określenie czy użytkownikowi chodzi o port 80 czy 443.
Można także uruchomić serwer, który nasłuchuje na innym porcie. Przykładem może tu być Tomcat, który domyślnie uruchamia się na porcie 8080. W takim przypadku podanie portu jest konieczne.
path
Ta część adresu URL jest ścieżką, która określa zasób. Na przykład w adresie https://us.strzelaj.xyz/co-to-sa-transakcje-elektroniczne-rodzaje-i-klasyfikacja/ ścieżką jest /co-to-sa-transakcje-elektroniczne-rodzaje-i-klasyfikacja.
query
Zawiera dodatkowe dane identyfikujące dany zasób. Ta część oddzielona jest od ścieżki znakiem ?. W praktyce zawiera pary klucz=wartość połączone znakiem &. Na przykład:
?parametr=wartosc&format=json
fragment
Ostatnia część adresu URL. W praktyce wykorzystywana jest do określenia fragmentu strony HTML, która powinna zostać pokazana użytkownikowi. Na przykład adres https://us.strzelaj.xyz/co-to-sa-transakcje-elektroniczne-rodzaje-i-klasyfikacja/#Literatura przenosi do sekcji wymieniającej literaturę użytą do przygotowania tego tematu.
Pisząc bardziej formalnie, fragment używany jest do określenia „podzbioru” zasobu (ang. secondary resource). W przypadku HTML zasobem jest strona HTML, a podzbiorem sekcja tej strony. Zgodnie ze specyfikacją ta część adresu URL służy do identyfikacji zasobu wyłącznie po stronie klienta. Oznacza to tyle, serwer do identyfikacji zasobu nie używa tej części URL.
Sesje
Można powiedzieć, że sesja to połączenie kilku żądań/odpowiedzi w jedną całość. Dzięki temu aplikacja webowa może powiązać te żądania z jednym użytkownikiem. Sesje najczęściej zaimplementowane są przy pomocy ciasteczek. Specyfikacja serwletów określa nawet domyślną nazwę takiego ciasteczka – jest to JSESSIONID.
Innym mechanizmem, na którym może być oparta sesja jest przepisywanie adresu URL (ang. URL rewriting). Polega ono na dołączaniu identyfikatora sesji do adresu. W takim przypadku adres może wyglądać następująco https://us.strzelaj.xyz/co-to-sa-transakcje-elektroniczne-rodzaje-i-klasyfikacja;jsessionid=1234. To kontener serwletów decyduje o metodzie, która powinna być użyta do “podtrzymywania” sesji.
Podobnie jak w przypadku ciasteczek sesja ma swój dedykowany obiekt. Po stronie serwera sesja reprezentowana jest przez HttpSession.
Czas trwania sesji
Sesja nie jest trzymana wiecznie. To jak długo powinna być utrzymywana przez kontener serwletów określone jest przez parametr metody setMaxInactiveInterval. Określa on w sekundach jak długo pomiędzy żądaniami klienta sesja powinna być utrzymywana.
Atrybuty sesji
Sesję można porównać do mapy, w której przechowujemy pary klucz-wartość. Są to atrybuty sesji. Dzięki nim mamy możliwość przekazywania informacji wewnątrz aplikacji webowej pomiędzy żądaniami klienta. Poniższy zestaw metod pozwala na pracę z atrybutami sesji:
getAttributeNames() getAttribute() removeAttribute() setAttribute()
Wartościami atrybutów są obiekty, jednak musimy pamiętać o tym, aby nie były one “duże”. Atrybuty sesji powinny być także serializowalne.
Mechanizm przechowywania sesji
Sesje mogą być przechowywane w pamięci kontenera serwletów. Nie jest to jedyna metoda ich przechowywania. Naiwny mechanizm może być oparty o ciasteczka, w takim przypadku wszystkie atrybuty sesji byłyby ciasteczkami.
Kontener serwletów do zapisywania sesji może użyć standardowych plików. Sesja może być także zapisana w różnych bazach danych. To w jaki sposób będzie to realizowane zależy od konfiguracji kontenera serwletów. W podstawowych przypadkach nie trzeba się przejmować tą konfiguracją.
Transakcje typu Cookie
Ciasteczka to mechanizm opisany w specyfikacji protokołu HTTP. W uproszczeniu można powiedzieć, że ciasteczka to informacje, które dołączane są do żądania i mogą być ustawiane w odpowiedzi. Ciasteczka połączone są z adresem, pod który wysyłane jest żądanie. Przeglądarka internetowa wysyłając żądanie pod adres www.utracki.us.edu.pl wyszukuje jakie ciasteczka ma zapisane dla tej domeny i dołącza je automatycznie do każdego żądania.
Po stronie serwera, w odpowiedzi można ustawiać ciasteczka. Można to robić przy pomocy nagłówka Set-Cookie. Z racji tego, że jest to bardzo popularny mechanizm istnieje osobny zestaw metod, które pomagają pracować z ciasteczkami:
addCookie() getCookies()
Samo ciasteczko reprezentowane jest przez klasę Cookie. Podstawowymi atrybutami ciasteczka jest jego nazwa i wartość.
Dodatkowo można ustawić też inne atrybuty, takie jak czas życia ciasteczka. Jeśli jest on ustawiony, wówczas przeglądarka dołącza ciasteczka do żądań tak długo jak są one “ważne”.
Przykładowy serwlet poniżej w odpowiedzi generuje stronę, która wyświetla wszystkie dostępne ciasteczka. Ustawia też jedno ciasteczko o nazwie custom-cookie, jego czas życia ustawiony jest na 10 sekund.
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
PrintWriter responseWriter = resp.getWriter();
responseWriter.write("<html><body>");
for (Cookie cookie : req.getCookies()) {
responseWriter.write("<p>" + cookie.getName() + " " + cookie.getValue() + "</p>");
}
Cookie cookie = new Cookie("custom-cookie", "bum bum cyk cyk");
cookie.setMaxAge(10);
resp.addCookie(cookie);
responseWriter.write("</body></html>");
}
Przy drugim otworzeniu strony generowanej przez ten serwlet można zobaczyć ciasteczko custom-cookie
Zastosowanie ciasteczek
Jak wiadomo protokół HTTP jest bezstanowy. Ciasteczka pomagają obejść tę właściwość. Bardzo często ciasteczka wykorzystywane są do zapisania informacji czy użytkownik jest zalogowany w aplikacji. Aplikacja sprawdza czy takie ciasteczko istnieje, jeśli tak udostępnia użytkownikowi jakieś dane. Jeśli ciasteczka brakuje wówczas przekierowuje go na stronę logowania.
Po zalogowaniu aplikacja ustawia ciasteczko, które następnie dołączane jest do kolejnych żądań automatycznie.
Użytkownik ma możliwość ustawienia przeglądarki internetowej w ten sposób, aby nie zapamiętywała ciasteczek. Nie jest to popularne, co więcej może powodować nieprawidłowe działanie strony, ale warto wiedzieć, że jest taka możliwość.
Podobnie jak w przypadku nagłówków – w codziennej pracy z aplikacjami webowymi często nie używa się ciasteczek bezpośrednio. Dzieje się to niejako “w tle” – zewnętrzne biblioteki wykorzystują ten mechanizm.